What is overfitting and underfitting in machine learning?
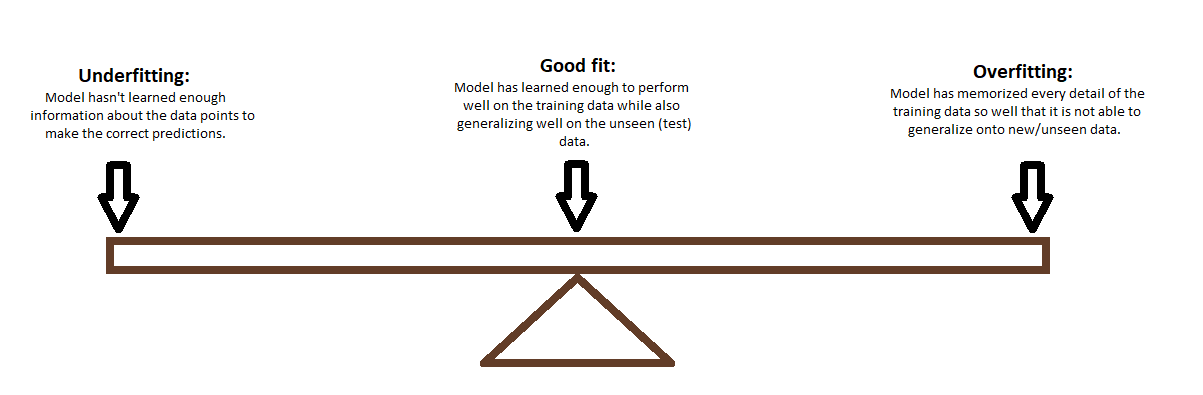
Models in machine learning underfit when they don’t learn enough information about the data they are fed to make the correct predictions. This can be due to not having enough training data or making the model too simple, which makes the model unable to capture the underlying trend of the data.
By comparison, overfitting happens when a model learns the
Illustration
Suppose this is our data set:
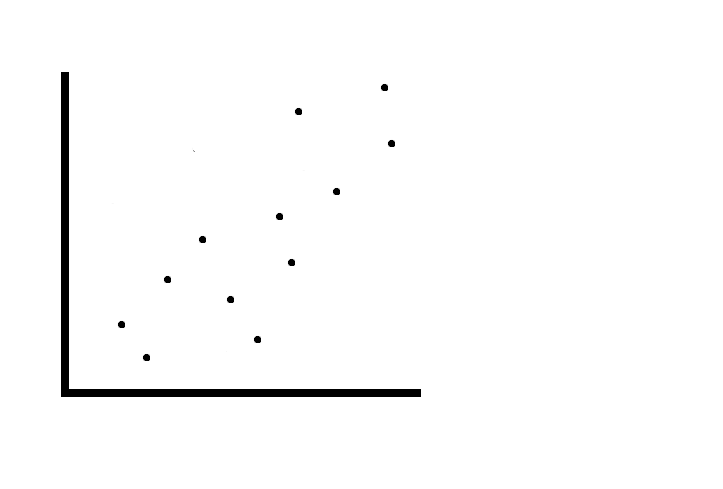
This could represent anything you can think of that has
Then these two possible diagrams would represent underfitting:
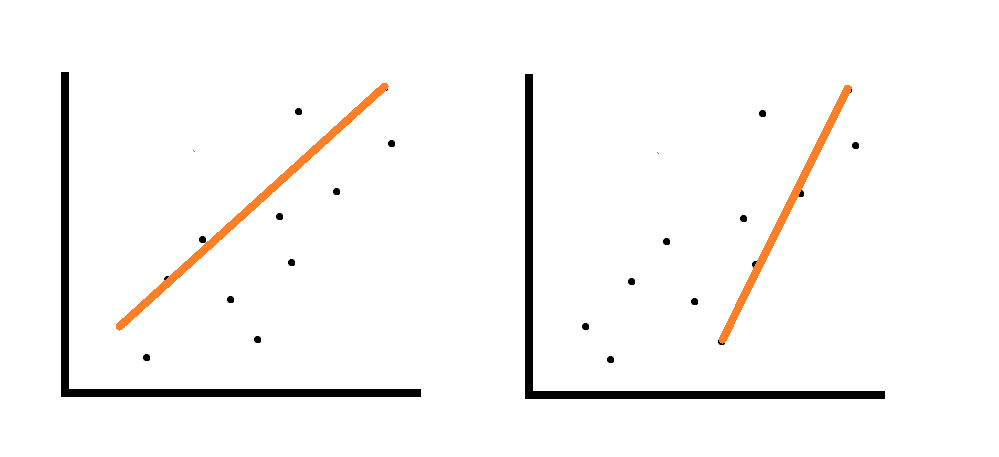
By contrast, overfitting is illustrated here:
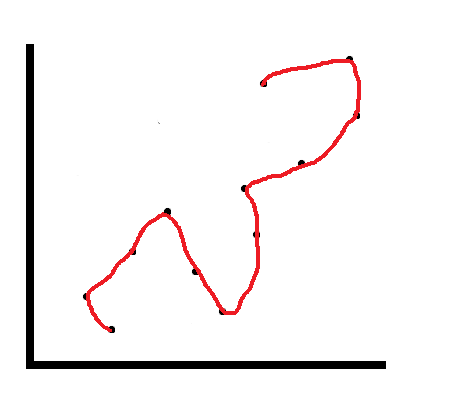
Ideally, what we want to achieve is something like this:
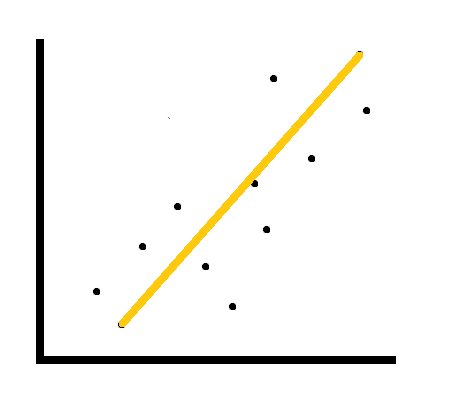
While it may not cover all the data points in this current set, there is a good chance that the learning algorithm used here could work well with new data. And this is the goal of every data scientist and analyst: to attain a good fit for their current data set that also generalizes well onto new data.
Bias, variance, and the trade-off
Overfitting and underfitting are often a result of either bias or variance.
Bias is when errors arise due to simplifying the assumptions in a model during training, leading to differences between the actual values and the predicted values.
On the other hand, variance is how often the model’s predictions differ when using different training data. It is caused by making the model really complex, which leads to overfitting since the model becomes so finely tuned to the training data, to the point of including noise when making predictions.
High bias and low variance leads to under-fitting, whereas high variance and low bias results in over-fitting. In order to have a model that provides a good fit, we need a bias-variance trade-off, which is a healthy balance between the two. It is worth noting that bias and variance are inversely proportional to each other; you cannot have high bias and high variance, or low bias and low variance.
Solutions to overfitting and underfitting
To reduce overfitting:
- Simplify the model to reduce model complexity
- Consider removing some features
- Introduce regularization
- Use cross-validation
- Use early stopping
To reduce underfitting:
- Increase model complexity
- Add more training data
- Carry out feature engineering
- Train for longer
- Reduce regularization
