What is Semantic Web?
The World Wide Web (WWW) has affected our daily lives in many ways. It has changed the way people communicate with each other (e.g., Facebook, Instagram, etc.), how information is retrieved (e.g., Google), and how business is conducted (e.g., Amazon). It lies at the heart of a revolution that is transforming the developed world towards a knowledge economy and, more broadly speaking, to a knowledge society.
The term Semantic Web comprises of techniques that promise to dramatically improve the current
Most of today’s Web content is suitable for human consumption as it is still not possible for machines to understand the data present on the Web. This means that data is not machine-accessible. Of course, there are tools that can retrieve texts, split them into parts, check the spelling, count their words, etc. But, when it comes to interpreting sentences and extracting useful information for users, current software capability is still very limited.
One approach is to represent Web content in a more easily machine-processable form and use intelligent techniques to take advantage of these representations. We refer to this plan of revolutionizing the Web as the Semantic Web initiative.
“The Semantic Web is an extension of the current web in which information is given well-defined meaning, better-enabling computers, and people to work in cooperation.”
Semantic web vision involves two basic concepts: Linked Open Data and Semantic Metadata.
Linked open data
Linked Data is one of the core pillars of the Semantic Web (also known as the Web of Data). The Semantic Web is about making links between datasets that are understandable to humans and machines. Linked Data provides the best practices for making these links possible. In other words, Linked Data is a set of design principles for sharing interlinked, machine-readable data on the Web.
Linked open data includes:
Factual data about specific entities and concepts (e.g., BigData, Machine Learning, Solar System, or the Global warming theory).
Ontologies, i.e., a semantic schema that defines:
- Classes of objects (e.g., Person, Organization, Location and Document).
- Relationship types (e.g., an owner of, a manufacturer of, or an author of).
- Attributes (e.g., the DoB of a person or the population of a geographic region).
-
Use URIs as names for things.
-
Use HTTP URIs so that people can look up those names.
-
When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL).
-
Include links to other URIs so that they can discover more things.
Basically, LOD(Linked Open Data) refers to Linked Data that is open. When data can be freely used and distributed by anyone, it is called Open Data.
Some of the famous LOD databases are DBpedia, GeoNames, Wikidata, and GRID(Global Research Identifier Database).
Semantic Metadata
Semantic Metadata amounts to semantic tags that are added to regular Web pages in order to better describe their meaning.
Such metadata makes it much easier to find Web pages based on semantic criteria – it resolves any potential ambiguity and ensures that when we search for Paris (the capital of France), we will not get results about Paris Hilton.
The
-
Resource Description Framework (RDF). A simple language for describing objects and their relations with a graph.
-
SPARQL Protocol and RDF Query Language (SPARQL). A protocol and query language for RDF data.
-
Uniform Resource Identifier (URI). A string of characters designed for the unambiguous identification of resources and extensibility via the URI scheme.
Architecture of Semantic Web
Tim Berners-Lee originally expressed the Semantic Web as follows:
“If HTML and the Web made all online documents look like one huge book, RDF, schema, and inference languages will make all the data in the world look like one huge database.”
The Layered architecture proposed by Time Berners-Lee for Semantic Web is shown below:
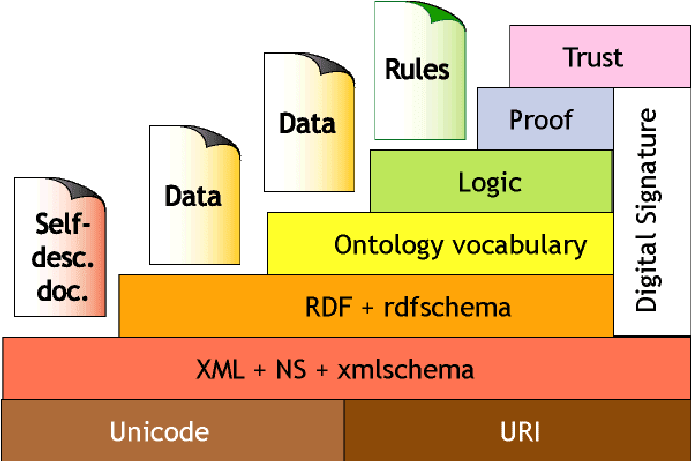
The main layers of the Semantic Web Architecture are:
-
Unicode and URI. Unicode is used to represent a character that is uniquely written in any language. Uniform Resource Identifier (URI) is a unique identifier for all resources. The functionality of Unicode and URI could be described as the provision of a unique identification mechanism within the stack for the semantic web.
-
XML. It is a language that lets one write structured Web documents with a user-defined vocabulary. XML is particularly suitable for sending documents across the Web.
-
RDF: Resource Description Framework is a basic data model, like the entity-relationship model, for writing simple statements about Web objects (resources). In other words, it’s a scheme for defining information on the Web. RDF provides the technology for expressing the meaning of terms and concepts in a form that computers can readily process.
-
RDF Schema. It provides a predefined, basic type system for RDF models. RDF Schema provides modeling primitives for organizing Web objects into hierarchies. Key primitives are classes and properties, subclass and sub-property relationships, and domain and range restrictions. RDF Schema can be viewed as a primitive language for writing ontologies
-
Ontology. The ontology layer describes properties and the logical relationship between different objects. Ontology can be defined as a collection of terms used to describe a specific domain with the ability of inference. An ontology is the explicit and formal specification of a conceptualization.
-
Logic layer. It is used to enhance the ontology language further and to allow for the writing of application-specific declarative knowledge.
-
Proof layer. It involves the actual deductive process as well as the representation of proofs in Web languages (from lower levels) and proof validation.
-
Trust layer. It will emerge through the use of digital signatures and other kinds of knowledge based on recommendations by trusted agents, rating and certification agencies, and consumer bodies.
Free Resources
- undefined by undefined
