What are the components of System Design?
Learn the essential components of system design, from load balancers and databases to messaging queues and monitoring systems, and discover how these building blocks work together to create scalable, reliable distributed systems.
Learning system design can give engineers and managers a serious advantage in the job market. It helps engineers by learning precisely why and when to make certain design decisions, and managers can better understand how these decisions affect business processes. The “building blocks” approach describes common core components of system design so that you can reattribute your knowledge to solve problems of any size. Because of its importance in real-world applications, system design is also a core focus in software engineer system design interview questions. Understanding these foundational elements helps candidates approach interviews with clarity and confidence.
The concept of system design is very complicated and constantly builds upon itself. This article covers the components or main building blocks of modern system design. If you want to familiarize yourself with some other basics of system design or other preliminary concepts like system design patterns or scalable web applications check out this article on the complete guide to system design.
Get hands on with system design.#
Try one of our 300+ courses and learning paths: Grokking Modern System Design for Software Engineers and Managers.
What is system design?#
At its simplest, system design is the process of defining: building blocks and their integration, APIs, and data models that all function together to create large-scale systems.
It is important to keep in mind that each system is designed to meet certain predetermined functional and non-functional requirements.
System design aims to build systems that are: reliable, effective, and maintainable
- Reliable systems handle faults, failures and errors.
- Effective systems meet all user needs as well as business requirements.
- Maintainable systems are flexible and easy to scale up or down. The addition of new features is simple in maintainable systems as well.
System design uses the concepts of computer networking, parallel computing, and distributed systems to build systems that perform and scale well. System design concepts build on a prior knowledge of distributed systems. In short, distributed systems are collections of computers that collaborate to form one cohesive computer for the end user. This style of system design architecture is known for scaling well but for being inherently complex.
System Design Deep Dive: Real-World Distributed Systems

Modern software systems are expected to operate at a massive scale while meeting strict reliability and latency requirements. Whether it’s a feed refresh, a payment request, or a real-time analytics query, users expect systems to respond instantly and consistently. That expectation has raised the bar for engineers today, understanding that System Design isn’t optional. It’s a core skill for building and evaluating production-grade systems. I built this course from my experience working on large-scale distributed systems at Microsoft (Azure) and Meta (Scuba), and from interviewing hundreds of candidates across both companies. The pattern I kept seeing was this: candidates understood individual components, but struggled to combine them into a coherent system. They knew what a cache or load balancer was, but not when or why to use it. This course is designed to bridge that gap. We start with the foundational building blocks of System Design, including databases, caching layers, load balancing, and messaging systems, and focus on how they interact under real-world constraints. From there, we analyze systems built by companies like Google, Facebook, and Amazon, breaking them down to understand the trade-offs behind each design decision. The goal is not just to learn concepts, but to develop the ability to reason through them in practice. This approach has helped a large number of engineers build stronger intuition for System Design and perform better in interviews. If you want to understand how real systems are designed and be able to design them yourself, this course gives you a clear, practical path forward.
The components of modern system design#
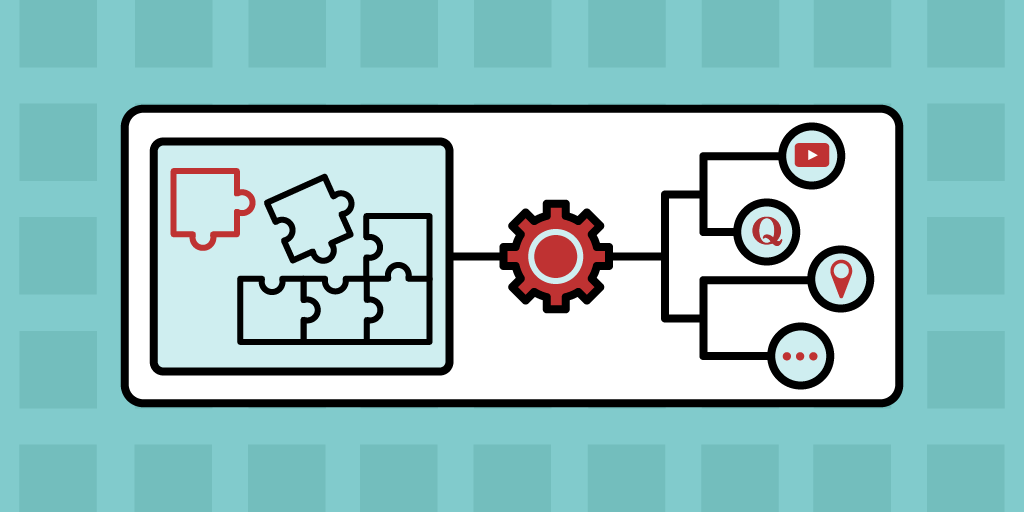
A more accurate term to describe these components is “building blocks.”
The idea of modern system design stems from the approach of piecing together building blocks to form one cohesive piece.
By treating separate system design concepts as building blocks to form a larger whole, we can break down complex problems in a digestible and understandable way. System design problems typically have some overarching similarities. However, most of the specific details are unique. By separating these unique building blocks and describing them one at a time, we can then utilize them as independent building blocks in system design. It is important to consider the software design patterns that we see when it comes to large-scale system design.
Many of the building blocks discussed in this article are also available for use in public clouds. You may be familiar with some of these services offered through Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
Learn more about the product design of the cloud computing service, Azure
Load balancers#
Load balancing is a key building block of system design. It involves delegating tasks over a set width of resources.
There may be millions of requests per second to a system on average. Load balancers ensure that all of these requests can be processed by dividing them between available servers.
This way, the servers will have a more manageable stream of tasks, and it is less likely that one server will be overburdened with requests. Evenly distributing the computational load allows for faster response times and the capacity for more web traffic.
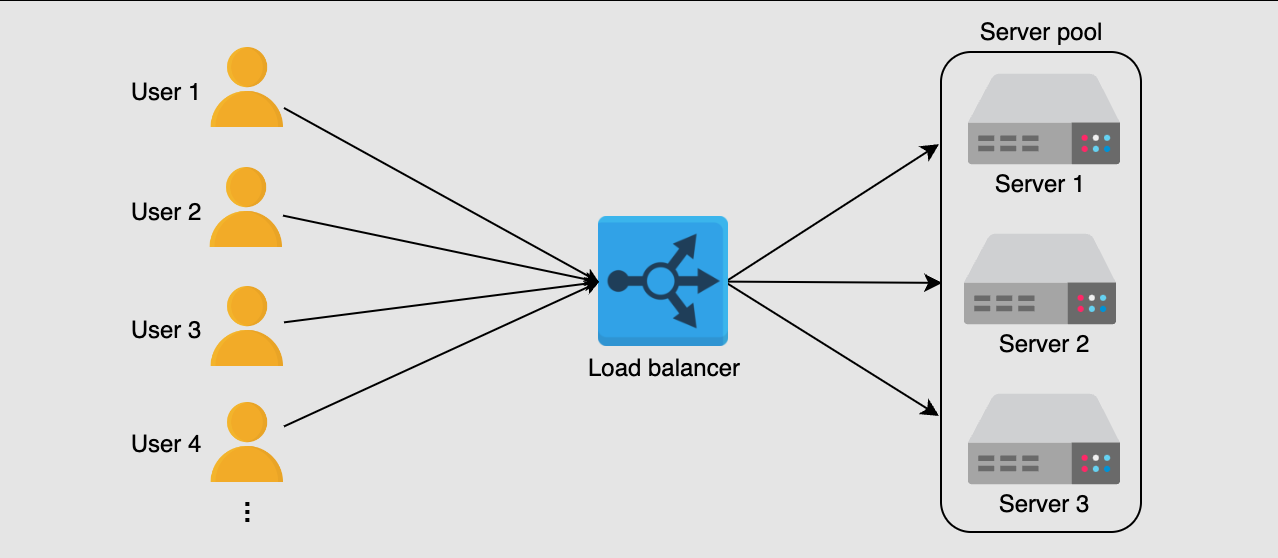
Load balancers are a crucial part of the system design process. They enable several key properties required for modern web design.
- Scaling: Load balancers facilitate scaling, either up or down, by disguising changes made to the number of servers.
- Availability: By dividing requests, load balancers maintain availability of the system even in the event of a server outage.
- Performance: Directing requests to servers with low traffic decreases response time for the end user.
Key value stores#
A key value store or key value database are storage systems similar to hash tables or dictionaries. Hash tables and dictionaries are associative as they store information as a pair in the (key, value) format. Information can easily be retrieved and sorted as a result of every value being linked to a key.
Key value stores are distributed hash tables (DHT).
Distributed hash tables are just decentralized versions of hash tables. This means they share the key-value pair and lookup methods.
The keys in a key value store treat data as a single opaque collection. The stored data could be a blob, server name, image, or anything the user wants to store. The values are referred to as opaque data types since they are effectively hidden by their method of storage. It is important that data types are opaque in order to support concepts like information hiding and object-oriented programming (OOP).
Examples of contemporary, large-scale key value stores are Amazon’s DynamoDB and Microsoft Cassandra.
Blob storage#
Blob, or binary large object, storage is a storage solution for unstructured data. This data can be mostly any type: photos, audio, multimedia, executable code, etc.
Blob storage uses flat data organization patterns, meaning there is no hierarchy of directories or sub-directories.
Most blob storage services such as Microsoft Azure or AWS S3 are built around a rule that states “write once, read many” or WORM. This ensures that important data is protected since once the data is written it can be read but not changed.
Blob stores are ideal for any application that is data heavy. Some of the most notable users of blob stores are:
- YouTube (Google Cloud Storage)
- Netflix (Amazon S3)
- Facebook (Tectonic)
These services generate enormous amounts of data through large media files. It is estimated that YouTube alone generates a petabyte (1024 terabytes!) of data every day.
Databases#
Traditional methods of file storage have significant limitations when it comes to scaling and flushing out the functionality of a system. The answer to these constraints is databases.
A database is an organized collection of data that can be easily accessed and modified. Databases exist to make the process of storing, retrieving, modifying, and deleting data simpler.
There are two basic types of databases:
- SQL, relational databases
- NoSQL, non-relational databases
In short, relational databases are structured, use a predetermined schema, and record data such as contact numbers and addresses. Non-relational databases are unstructured and use a dynamic schema. Non-relational databases are file directories that store information like personal profiles or shopping preferences.
Databases are an almost universal building block of system design, and there is a lot to cover. To dive deeper into databases check out this Database design tutorial.
Rate limiters#
A rate limiter sets a limit for the number of requests a service will fulfill. It will throttle requests that cross this threshold.
Rate limiters are an important line of defense for services and systems. They prevent services from being flooded with requests. By disallowing excessive requests, they can mitigate resource consumption.
In some cases, rate limiters can perform a similar function to load balancers. In systems that process large amounts of data, they help to control the flow of data between machines.
Monitoring systems#
Monitoring systems are software that allow system administrators to monitor infrastructure. This building block of system design is important because it creates one centralized location for observing the overall performance of a potentially large system of computers in real time.
Monitoring systems should have the ability to monitor factors such as:
- CPUs
- Server memory
- Routers
- Switches
- Bandwidth
- Applications
- Performance and availability of important network devices
Distributed messaging queues#
A messaging queue is an intermediary between two connected entities known as producers and consumers. A producer creates messages and consumers receive and process them.

Messaging queues help improve performance through asynchronous communication since producers and consumers act independently of each other. As a result, a messaging queue helps to decouple or reduce dependency in the system. This improves reliability and allows for a simpler, less cluttered system design. In addition, asynchronous messaging facilitates scalability. More consumers can be added in order to compensate for increased load.
There are several different use cases for a distributed messaging queue.
- Sending emails: As the name suggests, a messaging queue enables sending emails. Many different services are required to send emails for any number of reasons including account verification and password resets.
- Data post-processing: Applications with multimedia support process images and video for different formats or platforms. This can be a time-consuming and resource-intensive process, but messaging queues enable offline processing in order to reduce end-user latency.
- Recommender systems: Many sites use cookies to personalize a user’s content. This system retrieves the user data and processes it. A messaging queue can be incorporated to make this process more efficient as background data processing can be time consuming.
Distributed unique ID generators#
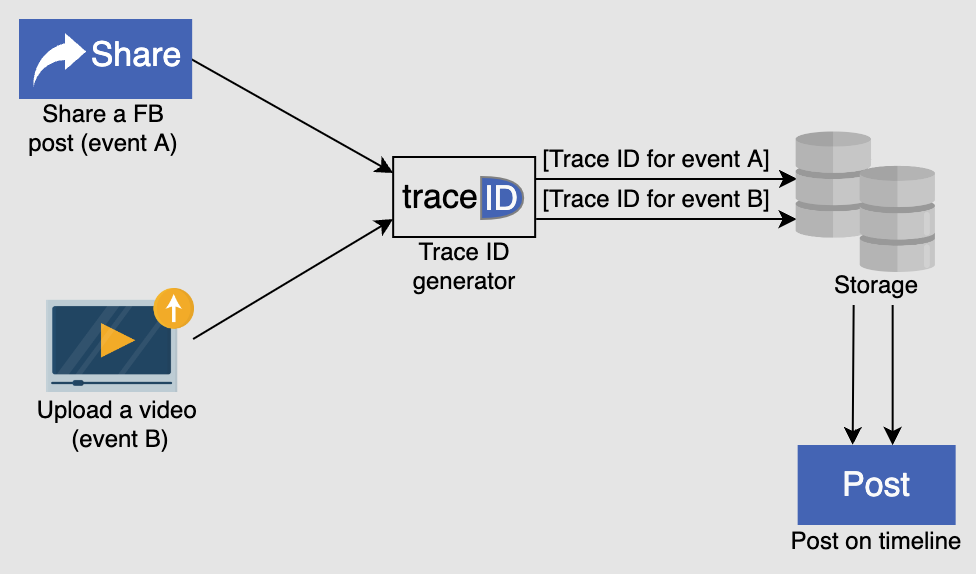
It is important to tag entities in a system with a unique identifier. Millions of events may occur every second in a large distributed system, so we need a method of distinguishing them. A unique ID generator performs this task and enables the logging and tracking of event flows for debugging or maintenance purposes.
In most cases this is a universal unique ID (UUID). These are 128 bit numbers that look like this: 123e4567e89b12d3a456426614174000 in hexadecimal. With a number this size, there is an enormous pool of possible IDs, but it is not completely guaranteed that all will be unique.
We can use a central database that takes a given ID and makes it unique by incrementing the value by one each time. Unfortunately, with a database solution there is one point of failure that can interrupt the entire ID generation process.
The concept of using a database can be diversified with a range handler. Range handlers feature multiple servers that each cover a range of ID values. One server may be assigned the values 100,000 to 300,000. Once it reaches ID 300,001 it will contact a central server to be assigned a new range of values. This increases accessibility allowing the system to stay live in the event of a failure.
Facebook’s own unique ID generator is called Canopy. Canopy uses a system called TraceID to enable end-to-end performance tracing.
Distributed search#
Search bars can be crucial for browsing large websites with hundreds or even thousands of pages. Most modern websites have search bars to help users find precisely what they’re looking for. Behind every search bar there is a search system.
Search systems are composed of three main entities:
- Crawler: finds/fetches content and creates documents
- Indexer: builds a searchable index
- Searcher: runs the search query against the index
Distributed search systems are reliable and ideal for horizontal scalability. A prime example of a digital product for distributed search is Elasticsearch.
Distributed logging services#
Logging is the process of recording data, in particular the events that occur in a software system. A log file is the recording of these details. They may document service actions, transactions, microservices, or any other data that may be helpful when debugging.
Logging in a distributed system is increasingly important as more and more designs move away from monolithic to microservice architectures. Logging in a microservice architecture is convenient because the logs can be traced along a flow of events from end-to-end. Since microservices can create interdependencies in a system, and a failure of one service can cascade to others, logging helps to determine the root cause of the failure.
Distributed task schedulers#
In computing, a task is a unit of work that requires computational resources for some specified amount of time.
These resources may be:
- CPU time
- Memory
- Storage
- Network bandwidth
It is important for tasks like image uploading or social media posting to be asynchronous as to not hold the user waiting for background tasks to end.
Task schedulers mediate the supply-demand balance between tasks and resources to control the workflow of the system. By allocating resources task schedulers can ensure that task-level and system-level goals are met in an efficient manner.
Task schedulers are used across a wide range of systems:
- Cloud computing services
- Large distributed systems
- Single-OS-based nodes
A notable example of a large distributed system task scheduler is Facebook’s task scheduler: Async.
Grokking Modern System Design for Software Engineers and Managers

For a decade, when developers talked about how to prepare for System Design Interviews, the answer was always Grokking System Design. This is that course — updated for the current tech landscape. As AI handles more of the routine work, engineers at every level are expected to operate with the architectural fluency that used to belong to Staff engineers. That's why System Design Interviews still determine starting level and compensation, and the bar keeps rising. I built this course from my experience building global-scale distributed systems at Microsoft and Meta — and from interviewing hundreds of candidates at both companies. The failure pattern I kept seeing wasn't a lack of technical knowledge. Even strong coders would hit a wall, because System Design Interviews don't test what you can build; they test whether you can reason through an ambiguous problem, communicate ideas clearly, and defend trade-offs in real time (all skills that matter ore than never now in the AI era). RESHADED is the framework I developed to fix that: a repeatable 45-minute roadmap through any open-ended System Design problem. The course covers the distributed systems fundamentals that appear in every interview – databases, caches, load balancers, CDNs, messaging queues, and more – then applies them across 13+ real-world case studies: YouTube, WhatsApp, Uber, Twitter, Google Maps, and modern systems like ChatGPT and AI/ML infrastructure. Then put your knowledge to the test with AI Mock Interviews designed to simulate the real interview experience. Hundreds of thousands of candidates have already used this course to land SWE, TPM, and EM roles at top companies. If you're serious about acing your next System Design Interview, this is the best place to start.
How system design components work together#
One of the biggest challenges when learning system design is that each building block often appears to exist in isolation. In reality, modern distributed systems combine multiple components that work together to handle traffic, store data, and maintain reliability.
Component | Primary responsibility |
Load Balancer | Distributes incoming traffic |
Application Servers | Process requests and business logic |
Database | Stores structured data |
Cache | Reduces database load |
Messaging Queue | Handles asynchronous tasks |
Monitoring System | Tracks system health |
Imagine a user uploading a photo to a social media application. The request first passes through a load balancer, which routes traffic to an available server. The application server processes the request and stores metadata in a database, while the image itself may be stored in blob storage. A messaging queue can then trigger background tasks such as image resizing or content moderation. Throughout the process, monitoring and logging systems track performance and detect failures.
Understanding individual components is important, but understanding how they interact is what transforms system design from a collection of concepts into a practical engineering skill. Most large-scale systems are ultimately built by combining these building blocks in different ways to satisfy reliability, scalability, and performance requirements.
Get started with modern System Design today#
You should now have a solid idea of what it takes to design a system and why certain system design solutions are implemented. This is by no means a complete list of all the possible building blocks you may need on your system design journey, but they are a solid foundation to expand upon.
As mentioned, every building block in system design has functional and non-functional requirements that must be met.
After learning what each system does and why they are designed the way they are, we recommend learning how to meet these requirements to build systems yourself. We offer a brand new course designed by system design experts called Grokking Modern System Design for Software Engineers and Managers. This course outlines all of the aforementioned building blocks and more, and then goes on to introduce system-design scenarios of real-world applications.
There are five other building blocks integral to designing systems not discussed in this article. They are:
- Domain Name System (DNS)
- Content Delivery Network (CDN)
- Distributed Caching
- Publish-Subscribe System
- Sharded Counters
By the end, you will understand how to create and implement modern system design building blocks, as well as solve any potential system design problems posed in an interview.
Additionally, you’ll learn techniques, protocols, and design principles of large-scale distributed systems that have successfully stood the test of time. Just a few of these systems are:
- YouTube
- Uber
- Instagram, and many others
Happy learning!
