

![Image from Medium, [C++] Concurrency by Valentina](/api/page/6705609052258304/image/download/6277800983003136?collection_token=undefined&get_optimised=true "Image from Medium, [C++] Concurrency by Valentina")
Threading models in C++ are techniques for managing and executing multiple threads concurrently, improving application performance and responsiveness.
Table of Contents
A tutorial on modern multithreading and concurrency in C++
8 mins read
Apr 29, 2024
Share
In the modern tech climate, concurrency has become an essential skill for all CPP programmers. As programs continue to get more complex, computers are designed with more CPU cores to match.
The best way for you to make use of these multicore machines is the coding technique of concurrency.
In this tutorial, we’ll get you familiar with concurrent programming and multithreading with the basics and real-world examples you’ll need to know.
Here’s what we’ll cover today:
- What is concurrency?
- Methods of implementing concurrency
- Examples of multithreading
- C++ concurrency in action: real-world applications
- Resources
Get hands-on with C++ today
Modern C++ Concurrency: Get the most out of any machine
"Concurrency with Modern C++" is a journey through the present and upcoming concurrency features in C++. - C++11 and C++14 have the basic building blocks for creating concurrent and parallel programs. - With C++17 we have the parallel algorithms from the Standard Template Library (STL). That means that most STL based algorithms can be executed sequentially, parallel, or vectorized. - The concurrency story in C++ goes on. With C++20 we can hope for extended futures, co-routines, transactions, and more. In addition to explaining the details of concurrency in modern C++, this course gives you many interactive code examples; therefore, you can combine theory with practice to get the most out of it. Apart from theory, this course contains a lot of real-world scenarios and use-cases along with pitfalls and how to overcome them using best practices.
What is concurrency? #
Concurrency occurs when multiple copies of a program run simultaneously while communicating with each other.
Simply put, concurrency is when two tasks are overlapped. A simple concurrent application will use a single machine to store the program’s instruction, but that process is executed by multiple, different threads.
This setup creates a kind of control flow, where each thread executes its instruction before passing to the next one.
The threads act independently and to make decisions based on the previous thread as well. However, some issues can arise in concurrency that make it tricky to implement.
For example, a data race is a common issue you may encounter in C++ concurrency and multi-threaded processes. Data races in C++ occur when at least two threads can simultaneously access a variable or memory location, and at least one of those threads tries to access that variable.
This can result in undefined behavior. Regardless of its challenges, concurrency is very important for handling multiple tasks at once.
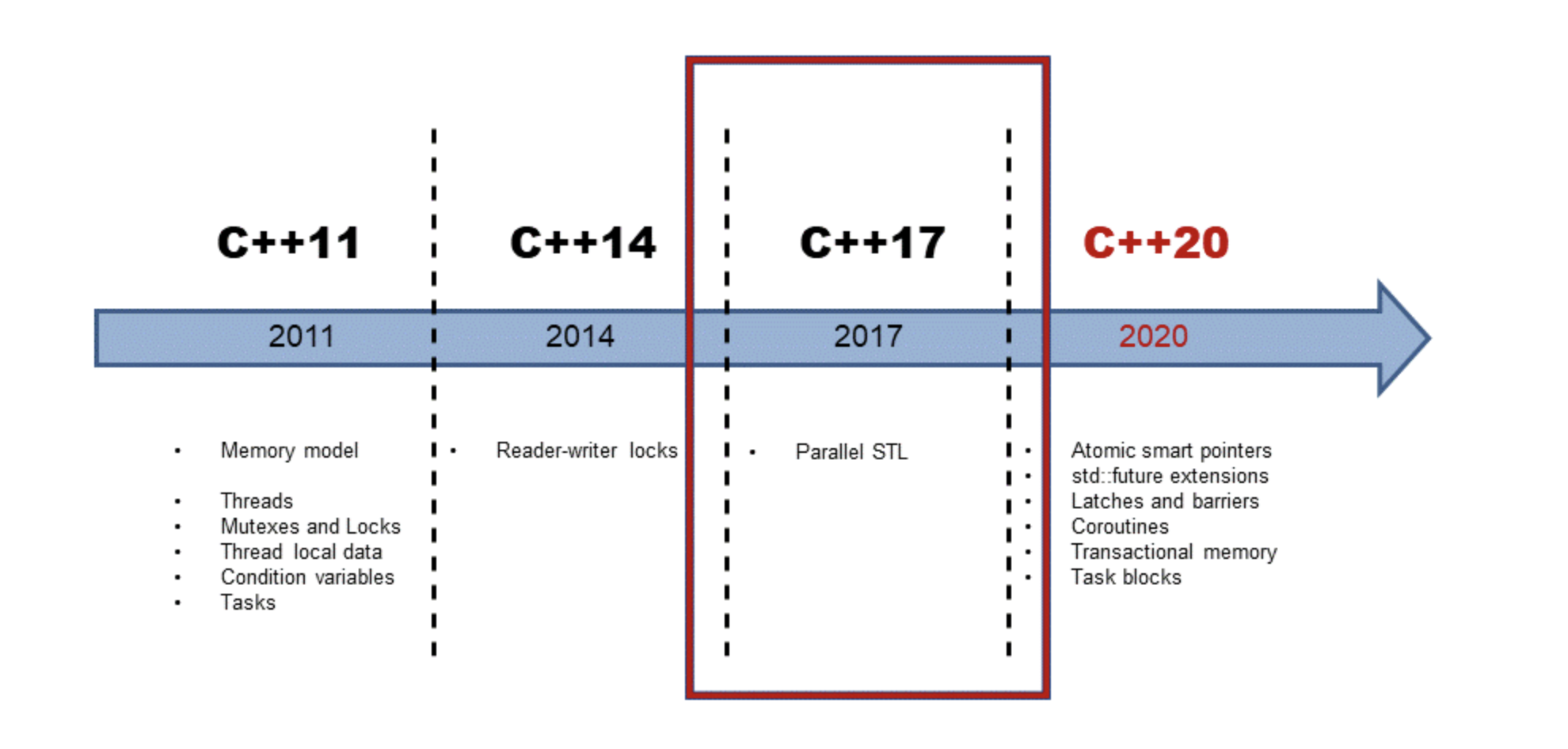
History of C++ concurrency#
C++11 was the first C++ standard to introduce concurrency, including threads, the C++ memory model, conditional variables, mutex, and more. The C++11 standard changes drastically with C++17.
The addition of parallel algorithms in the Standard Template Library (STL) greatly improved concurrent code.
Concurrency vs. parallelism#
Concurrency and parallelism often get mixed up, but it’s important to understand the difference. In parallelism, we run multiple copies of the same program simultaneously, but they are executed on different data.
For example, you could use parallelism to send requests to different websites but give each copy of the program a different set of URLs. These copies are not necessarily in communication with each other, but they are running at the same time in parallel.
As we explained above, concurrent programming involves a shared memory location, and the different threads actually “read” the information provided by the previous threads.
Image from EdPresso shot, "What is concurrent programming?"
Methods of Implementing Concurrency #
In C++, the two most common ways of implementing concurrency are through multithreading and parallelism. While these can be used in other programming languages, C++ stands out for its concurrent capabilities with lower than average overhead costs as well as its capacity for complex instruction.
Below, we’ll explore concurrent programming and multithreading in C++ programming.
C++ Multithreading#
C++ multithreading involves creating and using thread objects, seen as std::thread in code, to carry out delegated sub-tasks independently.
New threads are passed a function to complete, and optionally some parameters for that function.
Image from Medium, [C++] Concurrency by Valentina
While each individual thread can complete only one function at a time, thread pools allow us to recycle and reuse thread objects to give programs the illusion of unlimited multitasking.
Not only does this take advantage of multiple CPU cores, but it also allows the developer to control the number of tasks taken on by manipulating the thread pool size. The program can then use the computer resources efficiently without overloading becoming overloaded.
To better understand thread pools, consider the relationship of worker bees to a hive queen:
The queen (the program) has a broader goal to accomplish (the survival of the hive) while the workers (the threads) only have their individual tasks given by the queen.
Once these tasks are completed, the bees return to the queen for further instruction. At any one time, there is a set number of these workers being commanded by the queen, enough to utilize all of its hive space without overcrowding it.
Enjoying the article? Scroll down to sign up for our free, bi-monthly newsletter.
Parallelism#
Creating different threads is typically expensive in terms of both time and memory overhead for the program. Multithreading can therefore be wasteful when dealing with short simpler functions.
For times like these, developers can instead use parallel execution policy annotations, a way of marking certain functions as candidates for concurrency without creating threads explicitly.
At its most basic, there are two marks that can be encoded into a function. The first is parallel, which suggests to the compiler that the function be completed concurrently with other parallel functions. The other is sequential, meaning that the function must be completed individually.
Parallel functions can significantly speed up operations because they automatically use more of the computer’s CPU resources.
However, it is best saved for functions that have little interaction with other functions using dependencies or data editing. This is because while they are worked on concurrently, there is no way to know which will complete first, meaning the result is unpredictable unless synchronization such as mutex or condition variables are used.

Parallel execution of separate threads
Imagine we have two variables, A and B, and create functions addA and addB, which add 2 to their value.
We could do so with parallelism, as the behavior of addA is independent on the behavior of the other parallel function addB, and therefore has no problem executing concurrently.

Parallel functions that create unexpected outcomes
However, if the functions both impacted the same variable, we would instead want to use sequential execution.
Imagine that we instead had one which multiplied variable A by two, doubleA, and another which added B to A, addBtoA.
In this case, we would not want to use parallel execution as the outcome of this set of functions depends on which is completed first and would, therefore, result in a race condition.
While both multithreading and parallelism are helpful concepts for implementing concurrency in a C++ program, multithreading is more widely applicable due to its ability to handle complex operations. In the next section, we’ll look at a code example of multithreading at its most basic.
Get hands-on with C++ today.
Modern C++ Concurrency: Get the most out of any machine
"Concurrency with Modern C++" is a journey through the present and upcoming concurrency features in C++. - C++11 and C++14 have the basic building blocks for creating concurrent and parallel programs. - With C++17 we have the parallel algorithms from the Standard Template Library (STL). That means that most STL based algorithms can be executed sequentially, parallel, or vectorized. - The concurrency story in C++ goes on. With C++20 we can hope for extended futures, co-routines, transactions, and more. In addition to explaining the details of concurrency in modern C++, this course gives you many interactive code examples; therefore, you can combine theory with practice to get the most out of it. Apart from theory, this course contains a lot of real-world scenarios and use-cases along with pitfalls and how to overcome them using best practices.
Multithreading Examples #
In the following examples, we’ll look at some simple multithreaded programs designed to use a print function which we declare at the beginning.
Simple One-Thread example#
Since all threads must be given a function to complete at their creation, we first must declare a function for it to be given. We’ll name this function print, and will design it to take int and string arguments when called. When executed, this code will simply report the data values passed in.
void print(int n, const std::string &str) {
std::cout << "Printing integer: " << n << std::endl;
std::cout << "Printing string: " << str << std::endl;
}
In the next section, we’ll initialize a thread and have it execute the above function. To do this, we’ll have the main function, the default executor present in all C++ applications, initialize the thread for the print function.
After that, we use another handy multithreading command, join(), pausing the main function’s thread until the specified thread, in this case t1, has finished its task. Without join() here, the main thread would finish its task before t1 would complete print, resulting in an error.
int main() {
std::thread t1(print, 10, "Educative.blog");
t1.join();
return 0;
}
Multi-Thread Example#
While the outcome of the single thread example above could easily be replicated without using multithreaded code, we can truly see concurrency’s benefits when we attempt to complete print multiple times with different sets of data. Without multithreading, this would be done by simply having the main thread repeat print one at a time until completion.
To do this with concurrency in mind, we instead use a for loop to initialize multiple threads, pass them the print function and arguments, which they then complete concurrently. This multithreading option would be faster one using only the main thread as more of the total CPU is being used.
Runtime difference between multithreading and non-multithreading solutions increasing as more print executions are needed.
Let’s see what a many-thread version of the above code would look like:
C++ concurrency in action: real-world applications #
Multithreading programs and multithreaded applications are common in modern business systems, in fact, you likely use some more complex versions of the above programs in your everyday life.
Example 1: Email Server#
One example could be an email server, returning mailbox contents when requested by a user. With this program, we have no way of knowing how many people will be requesting their mail at any given time.
By using a thread pool, the program can process as many user requests as possible without risking an overload.
As above, each thread would execute a defined function, such as receiving the mailbox of the identifier passed in, void request_mail (string user_name).
Example 2: Web Crawler#
Another example could be a web crawler, which downloads pages across the web. By using multithreading, the developer would ensure that the web crawler is using as much of the hardware’s capability as possible to download and index multiple pages at once.
Based on just these two examples, we can see the breadth of functions in which concurrency can be advantageous. With the number of CPU cores in each computer increasing by the year, concurrency is certain to remain an invaluable asset in the arsenal of the modern developer.
Steps Forward and Resources #
In this article, we merely scratched the surface of what’s possible with multithreading and concurrency in C++.
To help you continue your concurrency journey, Educative has created the course Modern C++ Concurrency.
This course is full of insider tips, case studies, extensive sample code. By the end, you’ll have hands-on experience with concurrency projects on shared data, optimization, resolving data races, and more.
Continue reading about concurrency#
Frequently Asked Questions
What are the threading models in C++?
What are the threading models in C++?
Written By:
Ryan Thelin
Related Courses
Learn C++: The Complete Course for BeginnersC++20 STL CookbookC++ Fundamentals for ProfessionalsCompetitive Programming in C++: The Keys to SuccessC++ Programming for Experienced EngineersData Structures for Coding Interviews in C++Learn to Code: C++ for Absolute BeginnersModern CMake for C++Learning OpenCV from Scratch with C++Data Structures with Generic Types in C++Mastering Algorithms for Problem Solving in C++Beginner to Advanced Computing and Logic BuildingDecode the Coding Interview in C++: Real-World ExamplesCompetitive Programming - Crack Your Coding Interview, C++Implementing an Advanced Huge Integer Class
