Understanding racial bias in machine learning algorithms
Bias manifests itself everywhere in our world despite our best efforts to avoid it. Implicit bias refers to the attitudes, beliefs, and stereotypes that we hold about groups of people. Biases impact how we treat and respond to others, even when it’s involuntary.
Implicit bias is also pervasive in the tech industry, not only when it comes to hiring practices, but also in the products and technologies that well-intentioned developers create. In particular, researchers identify machine learning and artificial intelligence as technologies that suffer from implicit racial biases. If software development is truly “eating the world”, those of us in the industry must attend to these findings and work create a better world.
So, how do machine learning and AI suffer from racial bias? And more importantly, what can we do to combat it? Today will go over the following:
- Racial bias in machine learning and AI
- Combating racial bias in ML technologies
- Wrapping up and resources
Racial bias in machine learning and artificial intelligence#
Machine learning uses algorithms to receive inputs, organize data, and predict outputs within predetermined ranges and patterns. Algorithms may seem like “objectively” mathematic processes, but this is far from the truth. Racial bias seeps into algorithms in several subtle and not-so-subtle ways, leading to discriminatory results and outcomes. Let’s take a deeper look.
The danger of automation#
Algorithms can get the results you want for the wrong reasons. By automating an algorithm, it often finds patterns that you could not have predicted. The legend of the neural net tank experiment demonstrates this limitation of algorithms.
Automation poses dangers when data is imperfect, messy, or biased. An algorithm might latch onto unimportant data and reinforce unintentional implicit biases.
For example, data scientist Daphne Koller explained that an algorithm designed to recognize fractures from X-rays ended up instead recognizing which hospital generated the image. That algorithm now incorporates irrelevant data and skews results.
Imagine if an algorithm is exposed to racially biased data sets: it will continue to incorporate those biases, even in a completely different context.
Hiring algorithms especially fall victim to racial bias due to automation. Human resources managers cannot wade through pools of applicants, so resume-scanning algorithms weed out about 72% of resumes before an HR employee reads them. Resume scanners are typically trained on past company successes, meaning that they will company inherit biases.

In a well-known experiment, recruiters selected resumes with “white-sounding” names. By training an algorithm on that dataset, it learned to automatically filter out any “black-sounding” names. The algorithm selected candidates on purely subjective criteria, perpetuating racial discrimination.
This same form of automated discrimination prevents people of color from getting access to employment, housing, even student loans. Automation means we will create blind spots and racist biases in our so-called objective algorithms.
Improper training and proxies#
Algorithms are trained with data sets and proxies. Inputs can be biased, so algorithms too will become biased. Developers that train and test algorithms too often use data sets with poor representation of minorities. In fact, a commonly used dataset features content with 74% male faces and 83% white faces. If the source material is predominantly white, the results will be too.
This poses a significant problem for algorithms used in automatic demographic predictors and facial recognition software. Since facial recognition software is not trained on a wide range of minority faces, it misidentifies minorities based on a narrow range of features.
In a 2015 scandal, Google’s facial recognition technology tagged two black American users as gorillas due to biased inputs and incomplete training.
In another example from 2018, a facial recognition tool used by law-enforcement misidentified 35% of dark-skinned women as men. The error rate for light-skinned men was only 0.8%.
At a time when police brutality in the United States is at a peak, we can see how this biased data could lead to disastrous, even violent results.
Proxies also generate bias. A proxy, simply put, is an assumption about our variables that we use to get particular results. BMI, for example, is a proxy to label if someone is “healthy” or “unhealthy”.
We assume that BMI equates health, so we categorize bodies according to that system, though the concept of the BMI has widely been debunked. If we assume a proxy is accurate, we assume the results are as well.
This happens in machine learning.
A 2019 study revealed that a healthcare ML algorithm reduced the number of black patients identified for extra care by half. In fact, the risk score for any given health level was higher for white patients.
Since the algorithm was trained on the proxy of healthcare costs, it assumed that healthcare costs serve as an indicator for health needs. However, black patients spend less on healthcare for a variety of racialized systemic and social reasons.
Without deeper investigation, the results could have led to the allocation of extra resources only to white patients. When the algorithm was altered to include more accurate markers of health risk, the numbers shifted: black patients referred to care programs increased from 18% to 47% in all cases.
Example after example proves that machine learning training and proxies, even those created by well-intentioned developers, can lead to unexpected, harmful results that frequently discriminate against minorities.
AI bias is human bias#
Algorithms are not truly neutral. The notion that mathematics and science are purely objective is false. In fact, scientific discoveries throughout history, such as phrenology and even evolution, have been used to justify racist conclusions.
Algorithms are our opinions written in code. Since algorithms are designed, created, and trained by data scientists, people like you and me, machine learning technologies unintentionally inherent human biases. This means that our machines are in danger of inheriting any biases that we bring to the table, even on a large scale.
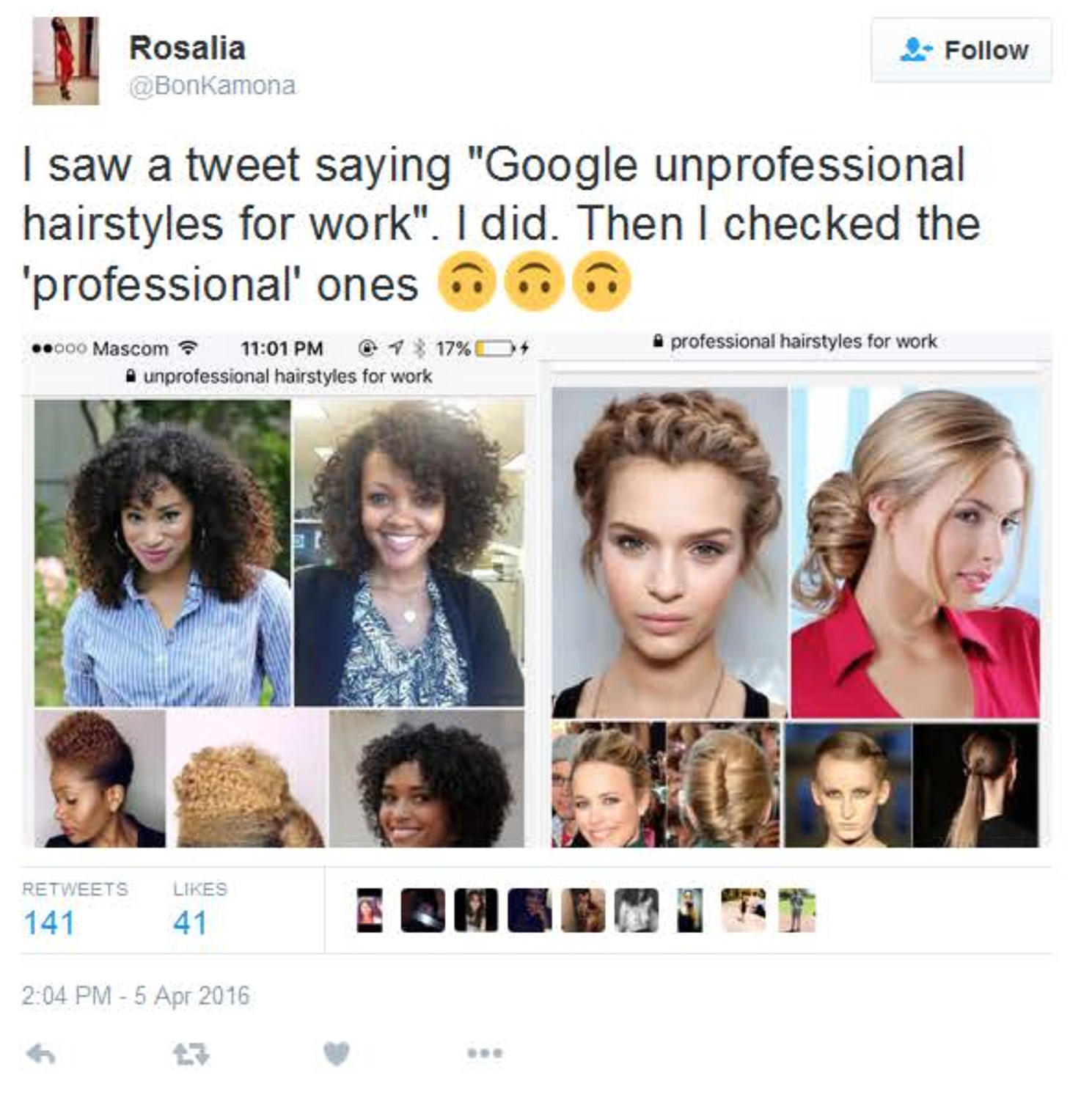
Source: TIME magazine on Google search algorithms
If you aren’t convinced, read up on Microsoft’s Tay, an AI chatbot that spread disturbingly racist messages after being taught by users in just a matter of hours.
AI bias is human bias. We are the teachers. It shouldn’t surprise you that representation is a contributing factor to this issue. A majority of AI researchers are males that come from white racial demographics, similar socioeconomic positions, even similar universities.
Studies from 2019 find that 80% of AI professors are men, and people of color remain underrepresented in major tech companies.
At a 2016 conference on AI, Timnit Gebru, a Google AI researcher, reported there were only six black people out of 8,500 attendees. This diversity crisis means that very few people of color are involved in machine learning decision-making or design.
If innovators are homogenous, the results and innovations will be too, and we’ll continue to ignore a wider range of human experience.
Combating racial bias in ML technologies#
The problem is real and apparent. So, how do we combat racial bias in machine learning? What can we actively do to prevent implicit bias from infecting our technologies?
Let’s take a look at a few suggestions and practices. I also recommend looking at the recource list for other practical solutions and research.
Train on accurate data & learning models#
Simply put, we must train algorithms on “better” data. Better data can mean a lot of different things. Training data should resemble the data that the algorithm will use day-to-day.
Data that has a lot of “junk” in it increases the potential biases of your algorithm. Avoid having different training models for different groups of people, especially if data is more limited for a minority group.
It isn’t possible to remove all bias from pre-existing data sets, especially since we can’t know what biases an algorithm developed on its own. Instead, we must continually re-train algorithms on data from real-world distributions.
We also need to choose the right learning model. There are benefits to supervised and unsupervised learning, and they must be taken into account depending on the program in question.
Human-generated data is a huge source of bias. It may not be malicious intent, but AI programs will reflect those biases back to us. So, we need to be cautious and humble when training algorithms.
Simply feeding algorithms more “diverse” data may not account for the implicit biases within that data. We must think critically about the potential data biases and turn to those more educated on the matter for feedback and instruction.
This presents us with the opportunity to address bias, not only in our technology but in ourselves as well.

Be intentional during the design phase#
The key to preventing racial bias occurs during the design phase. Many companies consider lowered costs to be the ultimate goal for algorithmic design, but this outcome has many blind spots. Data itself cannot account for histories of racial oppression and complex social factors when things like credit scores are used as proxies. Educate yourself on these histories before you design an algorithm and ask experts for input before committing to a particular design.
We must also code algorithms with a higher sensitivity to bias. We may not be able to “cure” bias, but we can act preventatively using checks and balances. Advocate for control systems and observations, such as random spot-checks on machine learning software, extensive human review on results, and manual correlation reviews.
We know that algorithms can create unintentional correlations, such as assuming that a person’s name is an indicator of potential employment, so we need to be vigilant and investigate why our algorithms are making their decisions.
Advocate for equity in the field#
It seems quite simple: diversity in the data science field could prevent technologies from perpetuating biases. The 2020 StackOverflow survey reveals that 68.3% of developers are white. This is a problem.
We need to start by hiring more people of color in ML fields and leadership positions without tokenizing their experiences. White business leaders should not expect candidates to act, speak, or think like them. The whole crux of diversity is the variety of perspectives that people bring with them, including different educational backgrounds.
However, hiring practices won’t change everything if the deeply embedded culture of the tech field stays the same. The norms, values, and language used to educate or recruit also matter. Many norms in the tech industry are exclusionary for minorities.
For example, the terms “tech guys” or “coding ninja” dissuade women and other minorities from applying to tech jobs. We need to launch strategies that change the culture and encourage underrepresented minorities to identify as developers. Even just calling out your coworkers for biased language is a good place to start.
We also need to increase increase access to resources. There are many myths out there about machine learning, i.e. that you need a Ph.D. from a prestigious university or that AI experts are rare. We need to change the narrative away from the notion that ML technologies are reserved for prestigious, mostly white scientists.
These myths prevent talented individuals from feeling included, seeking jobs, or even just getting started. Treating these tools with equity and open arms is a good place to start.

Change the way we educate on science and math#
As I mentioned before, science and mathematics are not necessarily objective. If we label data as “objective” or “factual”, we’re less inclined to think critically about the subjective factors and biases that limit and harm us. Science is taught as if it comes “out of nowhere”, as if there are no personal biases. But science and math are not exempt from social, historical, political, or economic factors.
Science happens amongst the “messiness” and complexity of human life. Let’s not ignore the world in the pursuit of the illusion of objectivity.
Part of this comes down to reimagining tech education. We won’t change the culture simply by recruiting employees or students who have already reached the later stages of the traditional educational pipeline. Instead, we need to rethink how we approach, teach, and segregate STEM+M from other fields.
One crucial change could be to encourage interdisciplinary education so that STEM students learn tech skills alongside art, history, literature, and more. We must also retell the history of tech to lift-up the often forgotten contributions of minority groups. These innovations and experiences are not a sub-section of tech history. They are the history of tech.
Wrapping up#
Algorithms can be terrible tools, and they can be a wonderful tool. What matters is how we create them, who we include in the process, and how willing we are to shift our cultural perspectives. At a time of division across our world, we often hear that we must work to be anti-racist.
Let us all consider how learning machine learning and designing algorithms must be approached as essential steps in creating anti-racist tools. Just as our personal biases are in our hands, so is the power to change them.
Continue to educate yourself and advocate for change in your workplace. Check out the resources below for more on this topic.
Sources and further reading#
Stanford Business on Racial Bias and Big Data
The Neural Net Tank Urban Legend
New York Times on AI and Racial Bias
Labor Market Discrimination and ML Algorithms
Demographic Estimation from Face Images
