



Cloud engineers have many career paths available depending on their interests and expertise. Some common roles include cloud architect, security engineer, DevOps engineer, solutions architect, and cloud consultant. Each position leverages specific skills and knowledge to help organizations effectively manage and optimize their cloud infrastructure.
Table of Contents
Roadmap to cloud jobs: How and why to become a cloud engineer
14 mins read
May 29, 2024
Share
As of 2019, over 50% of global enterprises use at least one public cloud platform for their everyday business operations. Today that number has jumped to nearly 68%, with many analysts predicting a similar, if not greater, jump into 2021. As the number of businesses migrating to the cloud continues to rise, cloud computing is set to become an over $330 billion industry by 2022 according to Indeed’s recent study.
For developers, this presents an amazing opportunity. Companies large and small will continue to seek out cloud computing expertise, offering some of the highest salaries in the tech domain. It can be tricky to know what skills and resume lines you’ll need to land one of these fresh jobs in cloud computing.
What does a cloud engineer actually need to learn?
What qualifications do they need to succeed?
Today, we’re going to walk you through all you need to know to become a cloud engineer. Here’s our roadmap to help you plan your next steps and jumpstart a career as a cloud developer.
Learn all you need to succeed in the cloud computing job market#
Take the first step toward a new profitable career, get industry-tailored lessons on all key concepts in cloud computing.
Why become a cloud engineer?#
The first and biggest reason is how quickly you can pick up cloud computing with a software background.
If you’re already a developer, you’re already halfway there. Going from software development to cloud engineering is only a slight pivot in terms of skills. In fact, many job offerings have overlaps between software and the cloud. If you are proficient in Java, Python, or SQL, you already fit a large portion of the hiring requirements for this position.
What’s the market like?#
This is the second reason: the demand for cloud engineers is big and only getting bigger. Cloud usage is on the rise meaning there are more job openings and security for cloud-capable engineers. The whole field of Cloud is opening and expanding.
In a recent Burning Glass survey, “Cloud Computing” ranked as the most requested skill for tech/development positions, appearing in over 90 thousand job listings - that’s more requested than both “Python ” and “Java” skills combined! This marks cloud computing as the best skill to increase your hireability in the modern tech climate.
This spike in demand has led to some very appealing salaries. According to Glassdoor’s most recent survey, Cloud Engineers across the industry make on average nearly $130k per year, about $40k more than Senior Software Developers.
Solve real-world problems#
On top of the market demand for cloud engineers, it’s also an exciting and fulfilling field. Cloud engineers get to solve real-world problems that affect people around the world.
Some cloud engineers work with large companies on security, storage, and accessibility, while others improve the daily lives of day-to-day people. In fact, cloud engineers are a huge contributor to the ease and accessibility of work-from-home lockdowns, making our world safer for people of diverse lifestyles.
On top of that, cloud computing involves creative and varied skills that branch off of software development. A job in cloud engineering utilizes skills in DevOps, web security, disaster recovery, containerization, networking, machine learning, and system design. You won’t be stuck in one domain and can explore the diverse facets of the cloud as a whole.
Cloud Development#
These programming jobs focus on developing the cloud architect’s vision into code on their respective platforms. They combine traditional development skills with cloud-specific knowledge to build, deploy, and optimize applications through the cloud. Cloud developers get to use their traditional software development skills alongside computer networking, app development, UI, and UX, amongst others
Some job titles in this category would be:
- Cloud Engineer, $128k annually
- Cloud Developer, $98k annually
- Cloud Software Developer, $76k annually
Cloud Support#
This is a more service-related category, and the actual jobs tend to vary more than the others. These jobs involve working directly with cloud clients to help meet their needs and maintain individual cloud components. In cloud support, you get to be an expert on a specific cloud technology or hosting service and work with clients to ensure their success. Some cloud support positions also get to explore new technologies and troubleshoot solutions alongside cloud architects to resolve customer issues on a larger scale.
Some job titles in the category would be:
- Cloud Support Engineer, $55k annually
- Cloud Security Engineer, $97k annually
- Cloud Systems Technician, $45k annually
What are the most popular cloud providers and platforms?#
There are many companies that provide cloud services for SaaS, PaaS, IaaS. Despite this, the world of cloud computing is generally run by a small group of cloud providers or services that host data. The cloud provider and platform you work with depends on the company you work for, with the most common being Amazon with AWS, Microsoft with Azure, and Google with the Google Cloud Platform.
Below you’ll find the cloud market share for each company, what their platform does well, and some notable companies that use the platform.
Amazon’s AWS
- Market share: 32%
- Main advantage: Largest breadth of available services at 175
- Notable Clients: Netflix, Linkedin, Twitch, Facebook, Twitter
Microsoft Azure
- Market Share: 18%
- Main advantage: Cost-effective for larger companies and those already using Microsoft products
- Notable Clients: eBay, Boeing, Samsung, BMW, Travelocity
Google GCP
- Market Share: 6%
- Main advantage: Strong support for open-source software and machine learning
- Notable Clients: Verizon, Facebook, Linkedin, Twitch, Intel, Yahoo
Many other providers specialize in particular cloud services or narrow their offerings. These include hosts like Dropbox, Oracle Cloud, Salesforce, and VMware. For example, Salesforce is a CRM tool that specializes in tracking company-to-customer relationships, or Red Hat, which is more focused on app development with Kubernetes.
If you are more interested in a particular aspect of the cloud or technology, you may consider researching their specialties.
Roadmap to becoming a cloud engineer#
Many developers want to become a cloud engineer, but it’s hard to know the steps to get there. Below is our 5 step roadmap to becoming a cloud engineer, including the most commonly requested skills by top companies like Amazon and Microsoft.
1. Study Software Concepts
- Proficiency in Java, AngularJS, and/or Python
- Bachelor’s Degree in Computer Science
- OR a Bootcamp with open source experience
2. Study Cloud Concepts
- Basics and Terms
- Deployment Models
- Auto-scaling
- Clustering
- Data Storage Infrastructure
- DevOps
- CI/DI
- Virtual Machines
- Global Deployments
- Cloud Security Practices
- Serverless Cloud Model
3. Learn Cloud Tools
- VMware
- DevOps Tools, Jenkins, Github, Ansible
- Containerization, Kubernetes, Docker
4. Get certified in a Cloud Platform
Note on certifications.
Certifications are a qualification awarded for passing one or more cloud platform proficiency exams from the respective cloud provider. Each major provider has a certification for their platform, with AWS and Azure being the most sought after by recruiters. These have quickly become a requirement for new cloud engineers and at least one is expected before a candidate will receive an interview.
5. Apply for Jobs
- Write a strong resume
- Prepare and study for your interview
Tip! Don’t limit yourself to just FAANG companies. Companies of all types are migrating to the cloud.
Necessary topics to learn for cloud engineers#
Now we know the basic steps you’ll need to take to become a cloud engineer. To help you along with this roadmap, we’ll break down just a few of the key concepts in detail from Step 2 and look closer at DevOps.
Cloud Basics and Terms#
Before jumping into more advanced cloud concepts, it’s essential to have a foundational understanding of what problems cloud computing was designed to solve, what components make up a cloud network, and the meaning of cloud terms often used in professional settings.
As a brief refresher, the cloud is a system of out-sourced data centers connected to an array of devices and users through the internet. This allows companies to have more centralized data and avoid set-up and maintenance costs.
The cloud is best understood if we divide it into the frontend (the client’s computer) and the backend (the cloud system). The backend consists of monitoring, databases, block storage, networks, computing power, queues, containers, runtime, and object storage. On the backend, there are multiple data storage systems and servers that host applications.
Data servers connect a user to their services through the internet, and a user can access, send, and modify files that are then forwarded to multiple servers. These storage resources can be accessed in multiple ways.
- End users with a web interface that pay for the cloud per-transaction
- A service provider dynamically issues resources on a pay-per-use basis
- Users with a specific capacity prepared for them by the service
Cloud client companies purchase specific cloud functions like storage, cloud environments, and cloud applications, called services from cloud providers such as Amazon, Microsoft, or Google.
Groups of services called service models are used to define to what extent the client company uses the cloud: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS).
To read more about cloud structures or service models, check out our previous article in this series, Cloud 101: Beginner’s Guide to Cloud Computing Concepts.
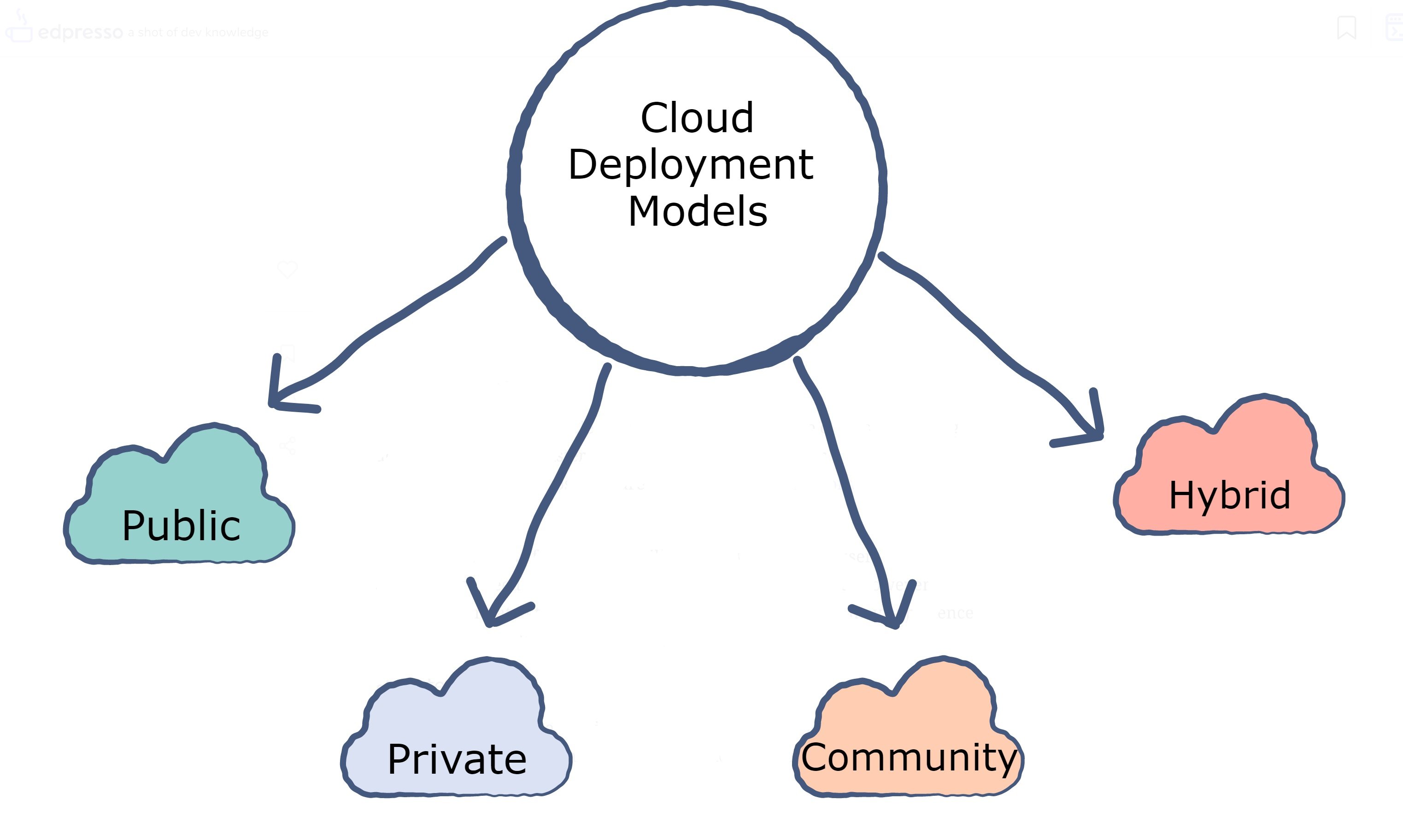
Deployment models#
In our previous article, we briefly covered deployment models by looking at private and public clouds. These are just two of the types of deployment models. Now we’ll look at hybrid clouds, multi-clouds, and community clouds.
Hybrid clouds combine the use of public and private clouds, running some modules with on-premise private clouds and others through public clouds. This allows companies to store sensitive data in private clouds while still using the benefits of public clouds for the bulk of their data.
Some companies, like LinkedIn and Facebook, get services from two or more cloud providers. This is called a Multi-Cloud environment. This is a common practice used by larger companies, as they can ensure they’re always using the provider’s strongest in the current task. These clouds can be all-public, all-private, or a mix of both.
The final deployment model, community cloud, is when a cloud is specially designed for a set of businesses that all need similar services. For example, a group of hospitals may need a cloud that supports a highly responsive, sortable, and encrypted medical record database hosted on the cloud. Community clouds ensure a level of standardization across a field of business and reduce the cost for each through a greater scale.
Keep the learning going.#
Find in-depth explanations and progression tracking quizzes, all written by a cloud engineering veteran who started where you are now. Educative’s courses are designed to work with busy developer schedules by being easy to skim and comfortable at any pace.
Auto-scaling#
Auto-scaling is a cloud feature that allows a program to dynamically spin-up more application instances in response to workload intensity. Cloud engineers are responsible for setting the auto-scaling configuration that decides when new instances are spun up and the maximum number of instances allowed.
Speed vs. CPU Cost
As a single application instance handles more workload, it gets slower like other programs. Another instance of the application can be spun up to split the workload and thus maintain the speed of service. These instances cost CPU, which taxes the server hardware and has a limit of how much can be used. Cloud engineers always try to maximize speed and minimize CPU, so they’re constantly working toward the optimal balance between the two.
All configurations use scheduled auto-scaling. This is where a cloud engineer sets a maximum number of instances or CPU usage to prevent new instances from being created if reached. This helps to manage costs, as computing power is expensive, and without this ceiling, our auto-scaler could call for an unlimited number of instances, each drawing considerable computing power.
Besides setting the scheduled auto-scaling ceiling, cloud engineers also determine which type of auto-scaling is most efficient for their company’s needs, either predictive auto-scaling or dynamic auto-scaling.
Predictive auto-scaling#
Predictive auto-scaling involves using machine learning and previous data to anticipate how many instances will be required to handle the workload at any given time. This is best used if your cloud’s workload has consistent periods of peak workload, as more instances don’t have to be spun up on the fly.
The downside is, if the workload is smaller than predicted, you pay more upkeep than is needed, or if the workload is too big, you must slow the product to spin-up more instances.
For example, when designing the auto-scaling policies for Netflix, it would be good to use predictive auto-scaling if you find that the application is consistently used more on weekends than on weekdays.
Dynamic auto-scaling#
Dynamic auto-scaling, on the other hand, spins up instances on the fly based on target metrics decided by the cloud engineer. Some common metrics are CPU usage, requests per minute on the program, or container resource usage. Most high level dynamic auto-scaling implementations utilize all of these metrics to ensure a sufficient number of instances.
This is best used when the cloud workload has no foreseeable pattern or remains mostly constant. The upside of this type of auto-scaling is that you’ll never have more instances than needed.
For the downside, the creation of instances on the fly can slow performance as current instances are overworked while the new one is spinning up. Also, if a key metric is missed, the program would not create a new instance when needed and run slowly as a result.
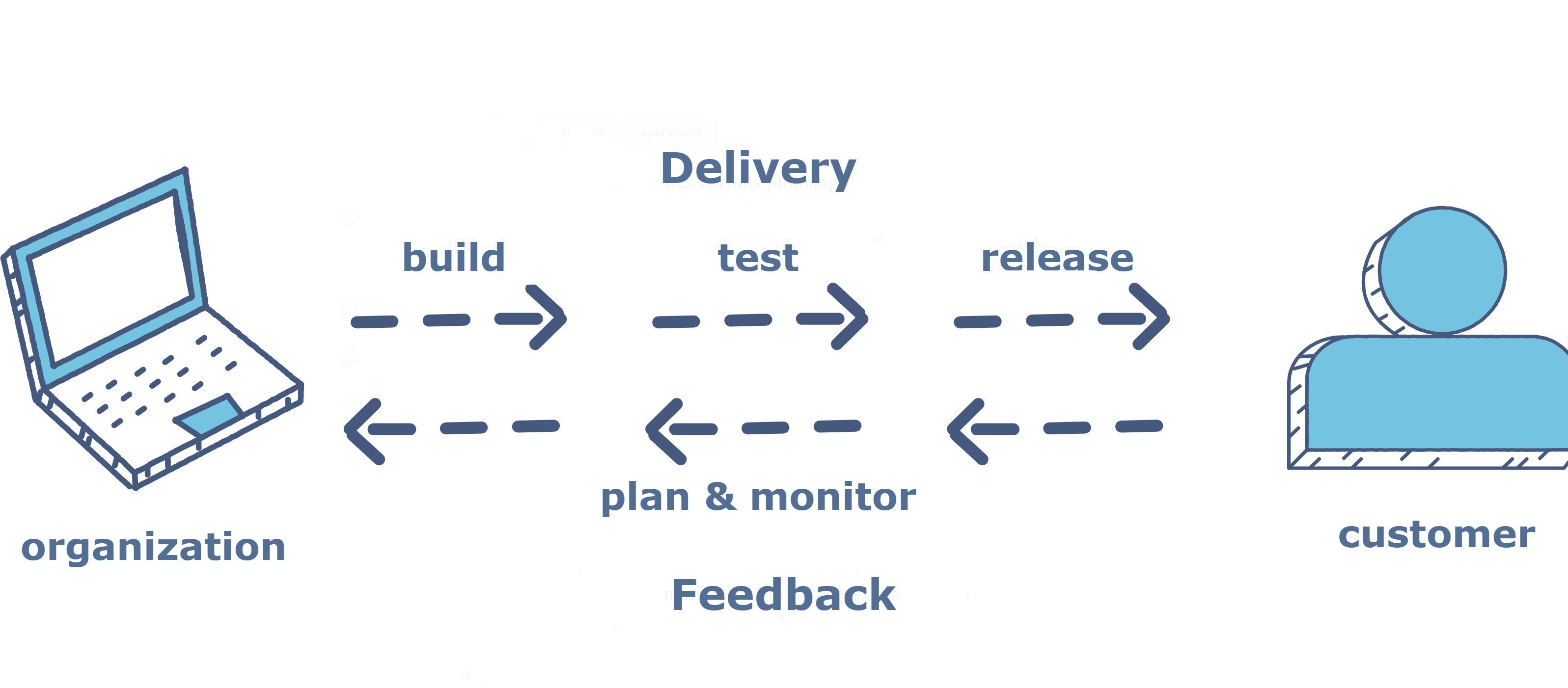
DevOps#
DevOps is a development strategy prevalent in cloud development teams that brings together the traditionally separate development and operations departments into a single team. The underlying goal of this strategy is to speed up application and service outputs by allowing operation feedback to come directly to the developers. This means that cloud engineers are expected to follow their application through its entire lifecycle, from conception to post-launch monitoring.
Another trend in DevOps teams is the automation of operations monitoring to streamline data collection and organization through software developed by the cloud engineers.
Therefore, in interviews, you should expect more critical thinking questions about disaster control or feedback response as well as questions on automated data management.
What to learn next#
As you continue your journey toward becoming a cloud engineer, you’ll need to expand your knowledge of cloud concepts and tools to stand out in the competitive market. Some next steps would be:
- Learn how to use AWS (the most popular cloud service)
- Master networking fundamentals
- Server clustering
- Global deployments
- CI/DI models
Educative’s course Cloud Computing 101: Master the Fundamentals is designed to jumpstart your cloud journey and guide you with interactive lessons perfect for a job-switching developer.
Through the 70 lessons, you’ll solidify your cloud foundation while also getting an expert step-by-step explanation of all the advanced topics brought up here. There’s no better tool for becoming a hirable, cloud-capable engineer of the future.
Further Reading on Cloud-related languages#
Frequently Asked Questions
What is the career path for a cloud engineer?
What is the career path for a cloud engineer?
Written By:
Ryan Thelin
Related Courses
SQL Interview Preparation—Intermediate LevelAce the Product Analytics Job InterviewData Science and Machine Learning Interview HandbookGrokking the Low Level Design Interview Using OOD PrinciplesGrokking the Coding Interview Patterns in C#MongoDB Interview PreparationGrokking Modern System Design InterviewSQL Interview PreparationGrokking the Product Architecture InterviewSystem Design Interview: Fast-Track in 48 HoursSQL Interview Preparation – Advanced LevelAlgorithms for Coding Interviews in JavaGrokking the Machine Learning InterviewMaster the JavaScript InterviewDecode the Coding Interview in C++: Real-World Examples
